Abstract
monkeSearch is an open-source, offline-first desktop search tool that allows you to find local files using natural language. Instead of relying on simple keyword matching, it uses embedding models to understand the semantic meaning of your query, allowing you to search for concepts, not just words. We made it Temporal Aware, such that it can parse time-related queries like "documents from last week" and apply them as filters. The entire process, from indexing to searching, runs locally on your machine. Our project utilizes different backends optimized for each OS to deliver the best performance and user experience across platforms.
Implementation Versions: There are multiple implementations in different branches written to achieve the same task for testing purposes. Rigorous evaluations and testing will be done before finalizing a single one for the main release.
For Agentic Use: The legacy LLM-based implementations (branches below) are particularly suitable for integration into larger AI pipelines and agentic systems. These versions allow direct filesystem access through natural language without modifying any files, leveraging OS-level scoped safety through Spotlight. If you're building autonomous agents or LLM orchestration systems that need file discovery capabilities, these branches provide a direct LLM-to-filesystem bridge without the overhead of maintaining a separate index.
- Initial implementation using LangExtract (Legacy – LLM based, ideal for agentic pipelines)
- Current main branch: LEANN-based (except Windows: Windows uses ChromaDB) semantic search with temporal awareness via regex parsing
-
llama.cpprewrite (legacy-main-llm-implementation) – deprecated but useful for direct LLM integration -
llama.cppfeature branch – another variation of thellama.cpprewrite, with a detailed response model
Cross-Platform Architecture

macOS: Uses the native Spotlight indexer for fast file discovery and a highly-optimized LEANN vector database for search.

Windows: Uses a standard os.walk file system crawl and ChromaDB for vector storage and retrieval.

Linux: Architecture similar to MacOS. Benchmarks coming soon!
Performance: macOS vs. Windows
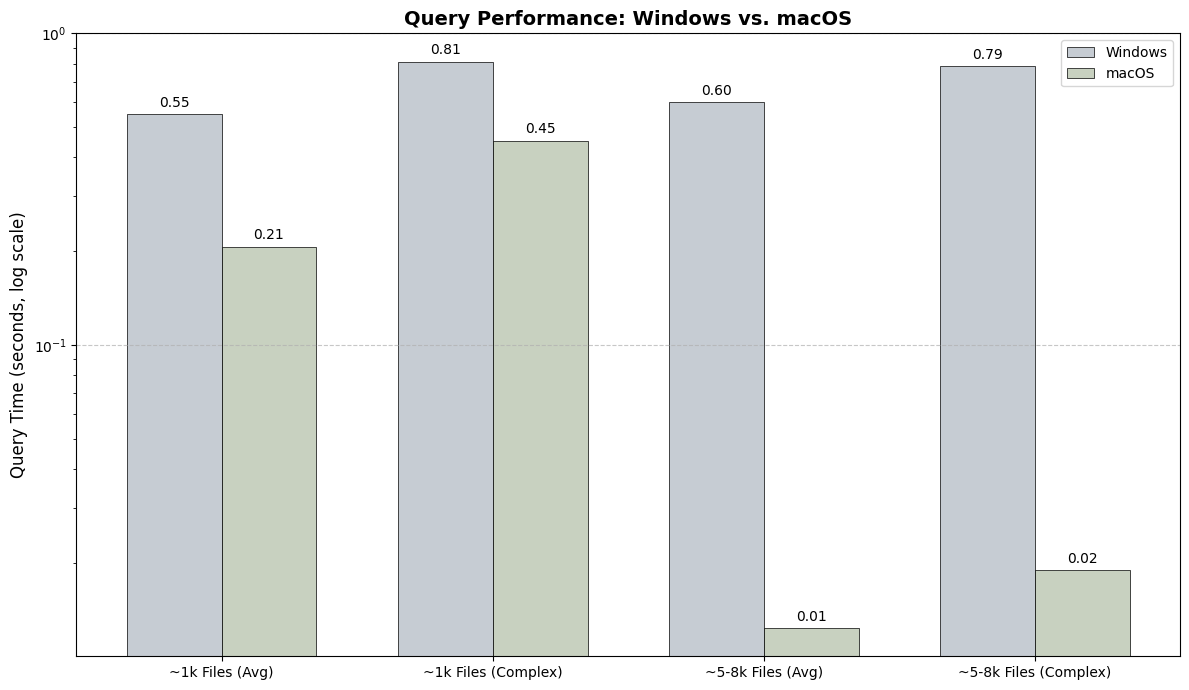
Query Time: macOS demonstrates significantly faster average search times due to its LEANN backend.
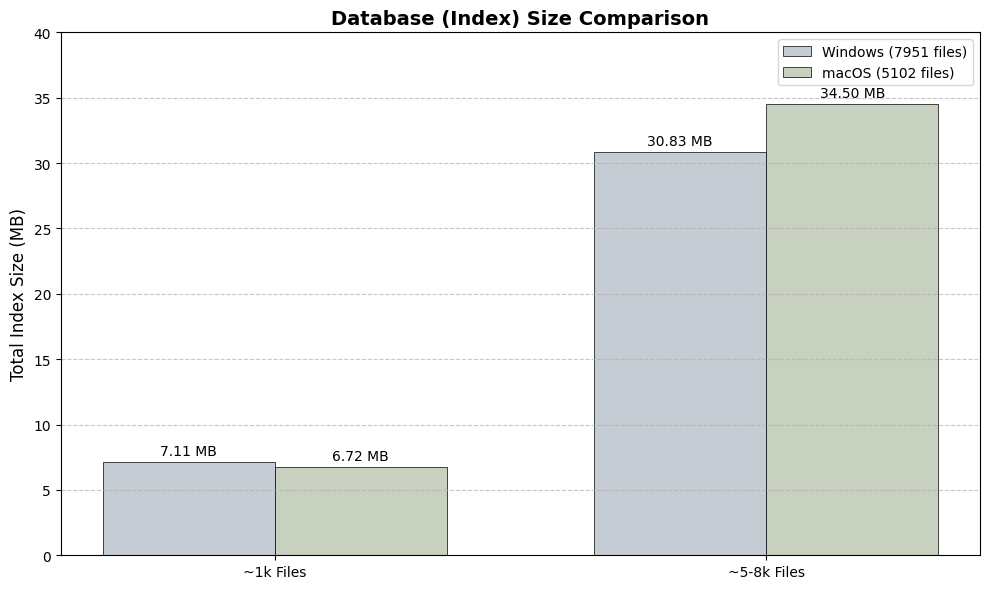
Index Size: On-disk size of the embedding database for different numbers of files.
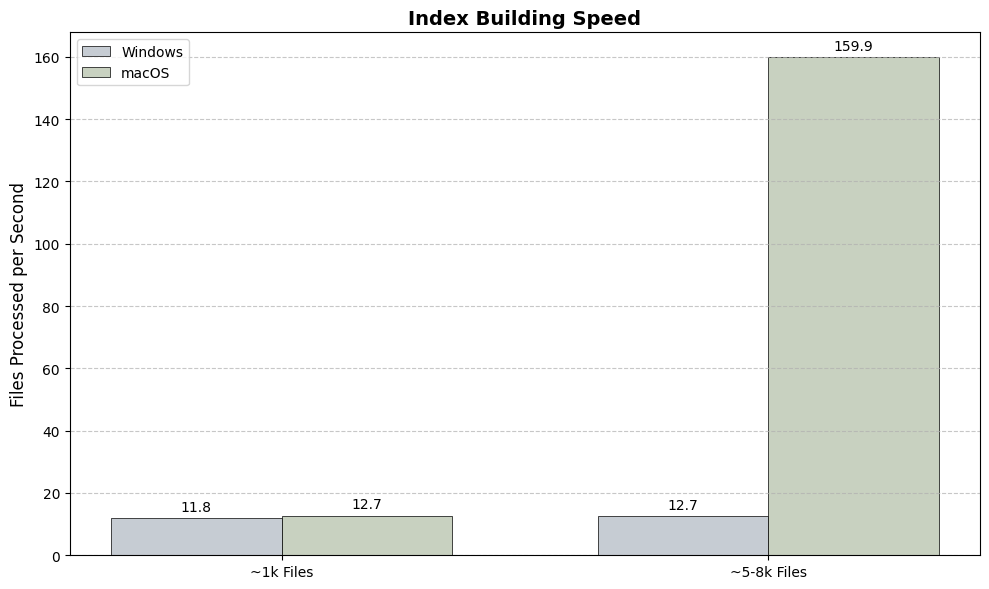
Indexing Speed: How many files per second each system can process during the initial build.
macOS Deep Dive: The Recompute Trade-Off
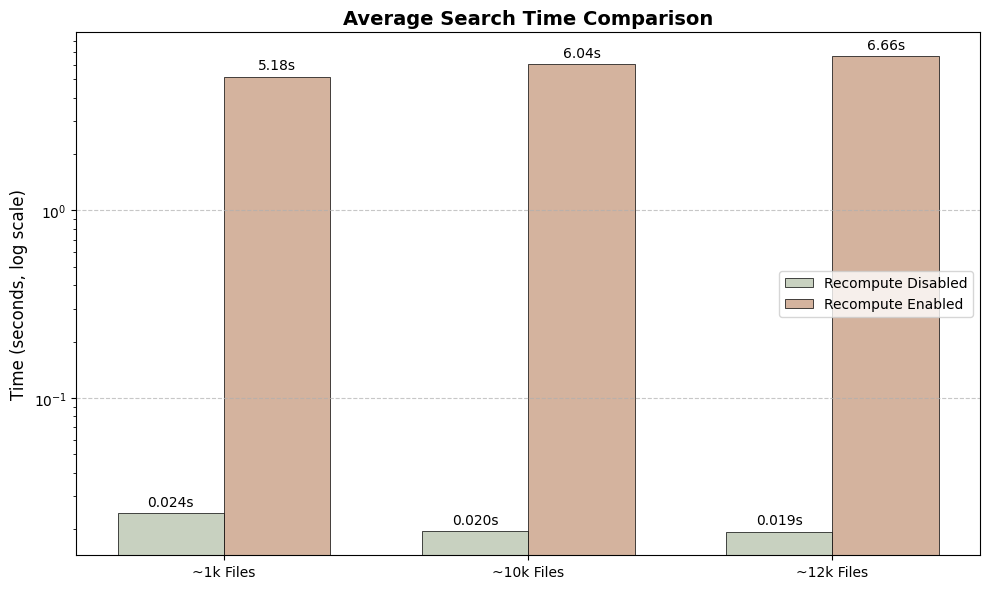
Search Speed: Disabling recompute yields lightning-fast searches (milliseconds), while enabling it dramatically slows down queries (seconds).
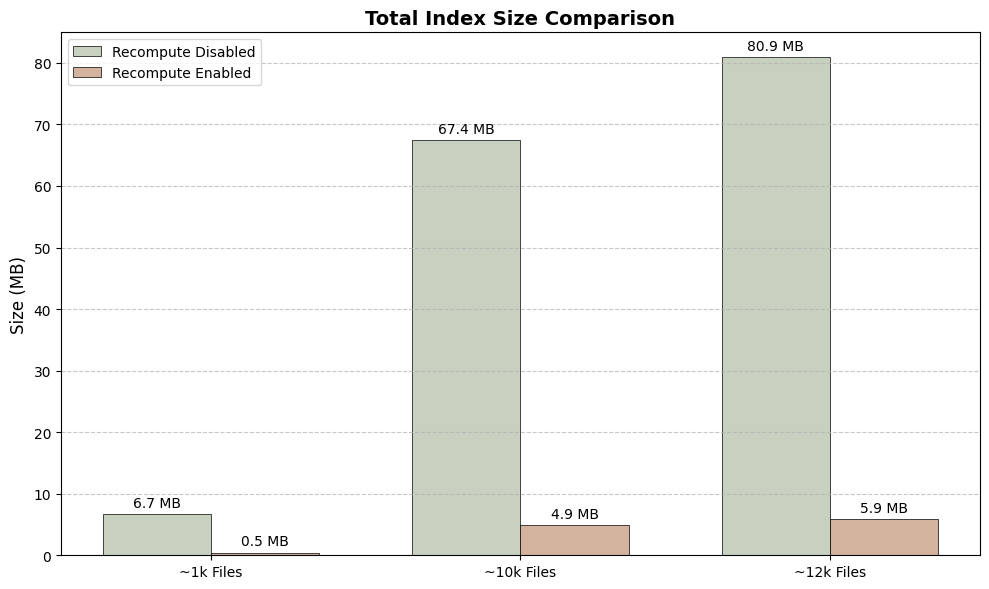
Space Savings: Enabling recompute creates a tiny index (over 97% smaller), saving significant disk space.
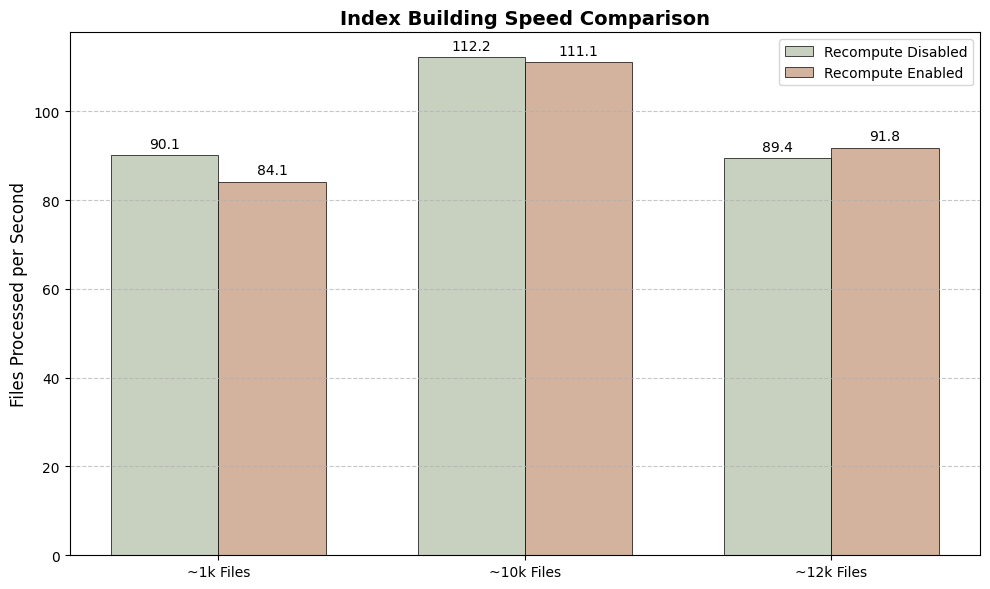
Build Speed: The initial indexing speed is nearly identical, as the main workload (embedding generation) is the same in both modes.
The "Recompute" feature on macOS offers a clear trade-off: enable it to save a massive amount of disk space at the cost of much slower search performance. Disable it for instant results, but with a larger storage footprint.
Support the Project
monkeSearch is an open source project. If you find it useful, please consider starring our repository on GitHub to show your support!
https://github.com/monkesearch/monkeSearch